의사결정나무
이번 시간에는 의사결정 나무 모델에 대해 살펴보도록 하겠습니다.
이번 시간 정리
의사결정 나무모델
- 지도학습 알고리즘 (분류, 회귀)
- 직관적인 알고리즘 (이해 쉬움)
- 과대적합되기 쉬운 알고리즘 (트리 깊이 제한 필요)
1. 라이브러리 및 데이터 불러오기
- 필요한 라이브러리를 가져오고, sklearn 라이브러리에 내장된 데이터를 불러옵니다
실행 완료
코드 실행
---------------------------------------------------------------------------
NameError Traceback (most recent call last)
/tmp/ipykernel_13/671062697.py in <module>
10 return X_train, X_test, y_train, y_test
11
---> 12 X_train, X_test, y_train, y_test = make_dataset()
13 X_train.shape, X_test.shape, y_train.shape, y_test.shape
/tmp/ipykernel_13/671062697.py in make_dataset()
4 def make_dataset():
5 iris = load_breast_cancer()
----> 6 df = pd.DataFrame(iris.data, columns=iris.feature_names)
7 df['target'] = iris.target
8 X_train, X_test, y_train, y_test = train_test_split(
NameError: name 'pd' is not defined코드 실행
---------------------------------------------------------------------------
NameError Traceback (most recent call last)
/tmp/ipykernel_13/3783099548.py in <module>
1 # 타겟 확인
----> 2 y_train.value_counts()
NameError: name 'y_train' is not defined2. 의사결정나무
- 지도학습(분류)에서 가장 유용하게 사용되고 있는 기법 중 하나입니다.
- 트리의 루트(root)에서 시작해서 정보이득이 최대가 되는 특성으로 데이터를 나눕니다.
- 정보이득(information gain)이 최대가 되는 특성을 나누는 기준(불순도를 측정하는 기준)은 '지니'와 '엔트로피'가 사용됩니다.
- 데이터가 한 종류만 있다면 엔트로피/지니 불순도는 0에 가깝고, 서로 다른 데이터의 비율이 비슷하면 1에 가깝습니다.
- 정보이득(information gain)이 최대라는 것은 불순도를 최소화 하는 방향입니다. (1-불순도)

코드 실행
---------------------------------------------------------------------------
NameError Traceback (most recent call last)
/tmp/ipykernel_13/1965012113.py in <module>
2 from sklearn.tree import DecisionTreeClassifier
3 model = DecisionTreeClassifier(random_state=0)
----> 4 model.fit(X_train, y_train)
5 pred = model.predict(X_test)
6 accuracy_score(y_test, pred)
NameError: name 'X_train' is not defined3. 의사결정나무 하이퍼파라미터
- criterion (기본값 gini) : 불순도 지표 (또는 엔트로피 불순도 entropy)
- max_depth (기본값 None) : 최대 한도 깊이
- min_samples_split (기본값 2) : 자식 노드를 갖기 위한 최소한의 데이터 수
- min_samples_leaf (기본값 1) : 리프 노드가 되기 위한 최소 샘플 수
※ 아래 코드에서 하이퍼 파라미터 값을 직접 조절해 보세요.
코드 실행
---------------------------------------------------------------------------
NameError Traceback (most recent call last)
/tmp/ipykernel_13/1626197471.py in <module>
7 min_samples_leaf=2,
8 random_state=0)
----> 9 model.fit(X_train, y_train)
10 pred = model.predict(X_test)
11 accuracy_score(y_test, pred)
NameError: name 'X_train' is not defined
이번 시간 정리
앙상블 방법
-배깅: 같은 알고리즘으로 여러 모델을 만들어 분류함(랜덤포레스트)
-부스팅: 학습과 예측을 하면서 가중치 반영 (xgboost)
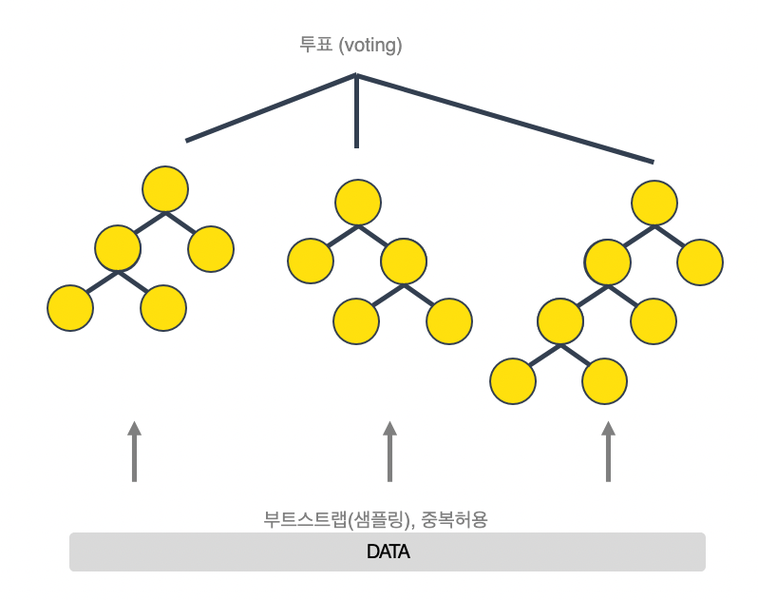
1. 랜덤포레스트
- 여러개의 의사결정 트리로 구성
- 앙상블 방법 중 배깅(bagging) 방식
- 부트스트랩 샘플링 (데이터셋 중복 허용)
- 최종 다수결 투표
- 과대적합 가능성 낮음
코드 실행
---------------------------------------------------------------------------
NameError Traceback (most recent call last)
/tmp/ipykernel_13/505913621.py in <module>
2 from sklearn.ensemble import RandomForestClassifier
3 model = RandomForestClassifier(random_state=0)
----> 4 model.fit(X_train, y_train)
5 pred = model.predict(X_test)
6 accuracy_score(y_test, pred)
NameError: name 'X_train' is not defined2. 랜덤포레스트 하이퍼파라미터
- n_estimators (기본값 100) : 트리의 수
- criterion (기본값 gini) : 불순도 지표
- max_depth (기본값 None) : 최대 한도 깊이
- min_samples_split (기본값 2) : 자식 노드를 갖기 위한 최소한의 데이터 수
- min_samples_leaf (기본값 1) : 리프 노드가 되기 위한 최소 샘플 수
※ 아래 코드에서 하이퍼 파라미터 값을 직접 조절해 보세요.
코드 실행
---------------------------------------------------------------------------
NameError Traceback (most recent call last)
/tmp/ipykernel_13/2863673619.py in <module>
2 from sklearn.ensemble import RandomForestClassifier
3 model = RandomForestClassifier(n_estimators=500, max_depth=5, random_state=0)
----> 4 model.fit(X_train, y_train)
5 pred = model.predict(X_test)
6 accuracy_score(y_test, pred)
NameError: name 'X_train' is not defined'언어 > 파이썬' 카테고리의 다른 글
| 머신러닝with파이썬5강(3)_분류모델평가, 회귀모델평가 (1) | 2024.03.12 |
|---|---|
| 머신러닝with파이썬5강(2)_XGBoost, 교차검증 (0) | 2024.03.11 |
| 머신러닝with파이썬4강(3)_사이킷런으로 머신러닝 진행하기, 사이킷런 공식문서 사이트 (0) | 2024.03.09 |
| 머신러닝with파이썬 4강(2)_데이터전처리: 범주형 데이터, 수치형 데이터 (0) | 2024.03.08 |
| 머신러닝with파이썬4강(1)_사이킷런 활용하기, 사이킷런에서 제공하는 데이터셋 (0) | 2024.03.07 |