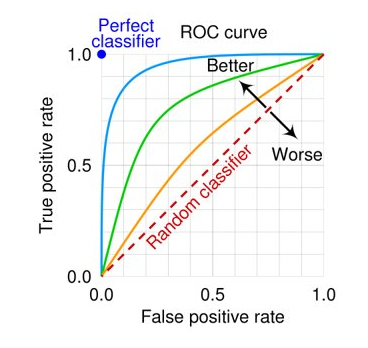
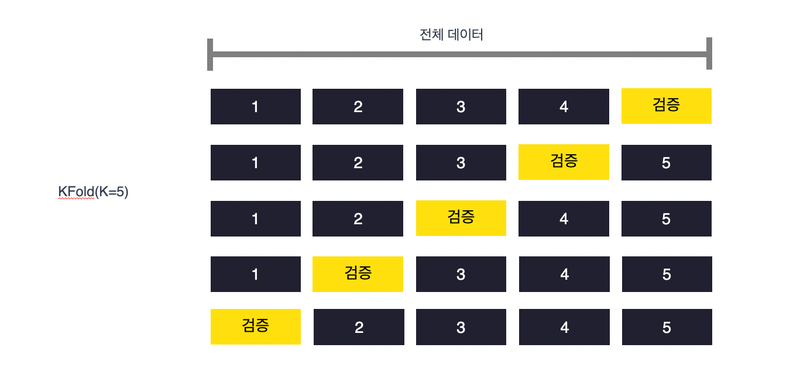
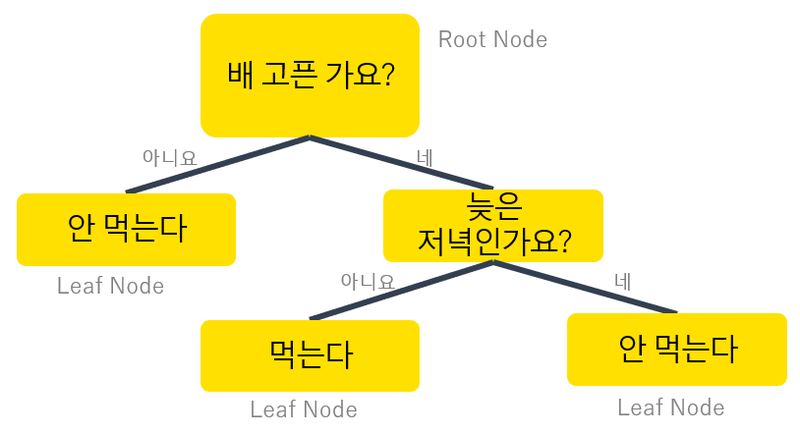
💡 Python : 데이터 분석, 프로토타입 개발 등에 쓰이는 인기 있는 인터프리터 기반 프로그래밍 언어. Python Welcome to Python.org 1991년에 네덜란드의 프로그래머 귀도 반 로섬(Guido Van Rossum)가 만든 고급 프로그래밍 언어이다. Interpreter-based, OOP, dynamic type binding을 지원한다. 이름은 귀도가 좋아하는 *“Monty Python’s Flying Circus”*에서 따왔다. (실제 python은 뱀이라는 의미) 예시 코드를 보면서 파이썬의 특징에 대해서 좀 더 이야기를 해보자. def say_welcome(name): print(f"Hello World! {name}!") my_name = "yongdam" say_wel..