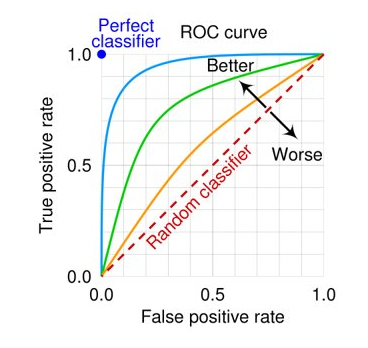
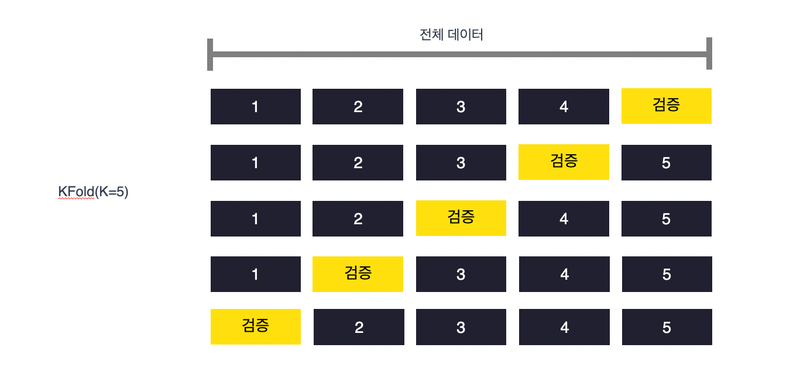
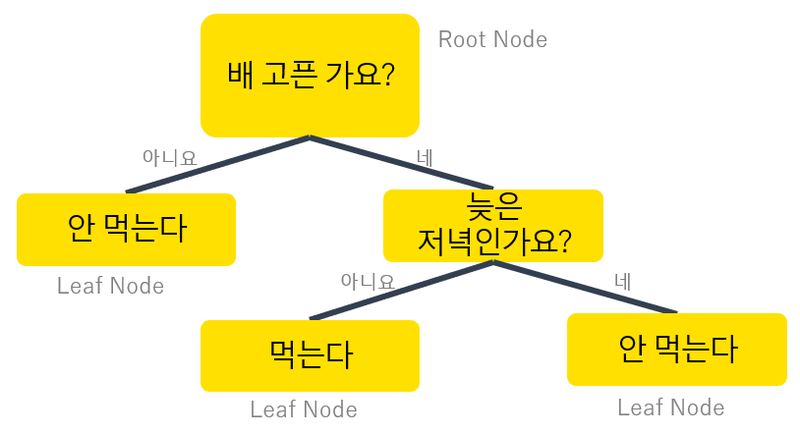
1. 선형회귀 단순 선형회귀와 다중 선형회귀가 있지만 흔히 사용하는 것은 다중 선형회귀입니다. Feature가 한 개인 경우가 드물기 때문에 보통 feature가 두 개 이상인 다중 선형회귀를 만들게 됩니다. 2. 비용함수 데이터와 모델 간의 거리를 계산합니다. 비용함수(cost function) 또는 손실함수, 목적함수라 부르기도 합니다. 오차(error)를 계산합니다. (실제 값과 예측값의 차이) 평균 제곱 오차를 최소화하는 파라미터를 찾습니다. 3. 경사하강법 오차를 찾아 나가는 방식 비용함수의 기울기 절대값이 가장 작은 지점을 찾아서 오차가 작은 모델을 만듭니다. # 라이브러리 불러오기 import pandas as pd from sklearn.model_selection import train_..